Speculative Decoding for 2x Faster Whisper Inference
What Happened
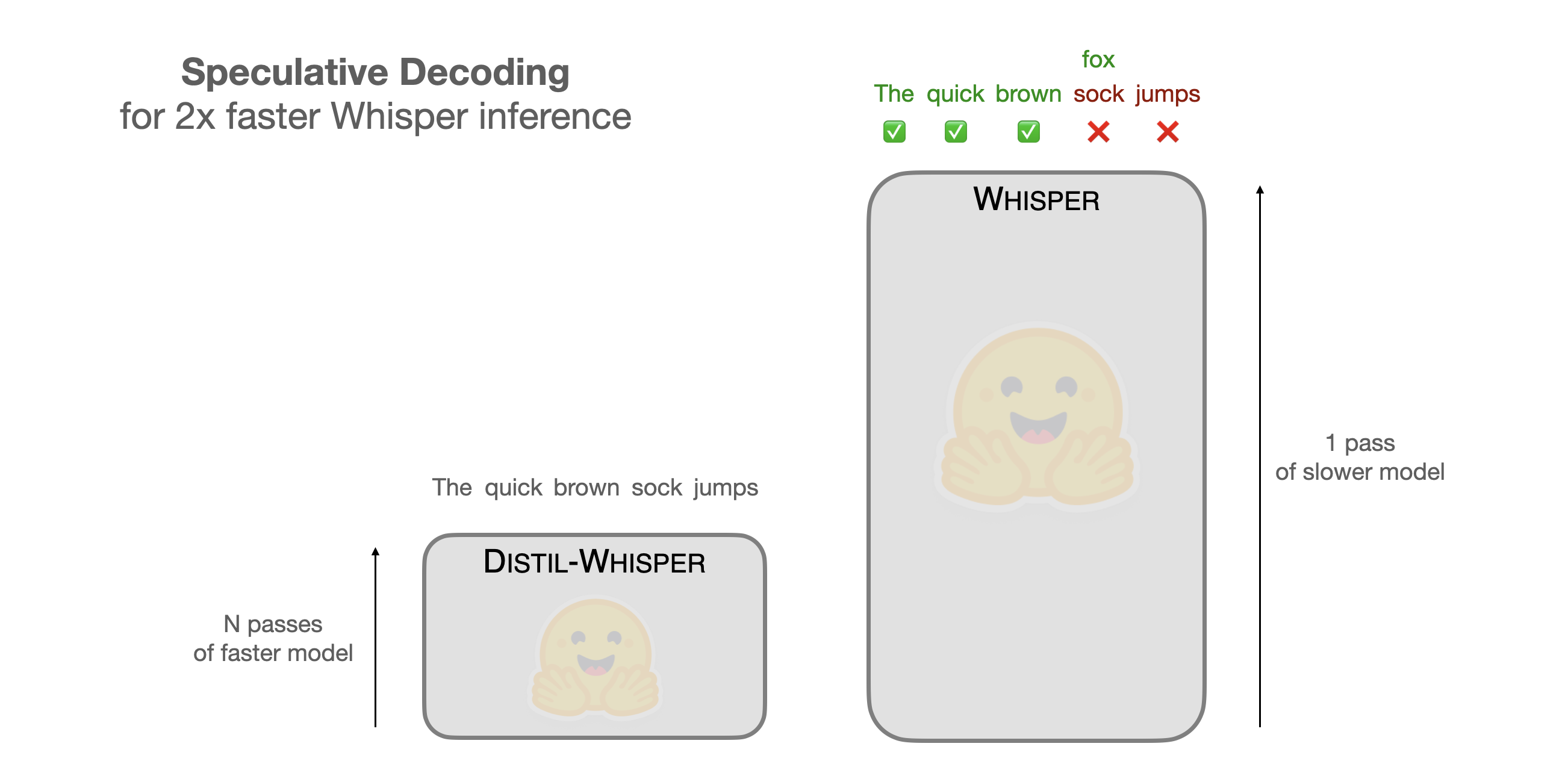
Speculative Decoding for 2x Faster Whisper Inference
Our Take
speculative decoding is pure optimization, and it actually works for inference. it’s not about making the model smarter; it’s about reducing the sequential token generation latency. we're talking about using a draft model to predict the next few tokens, and then verifying them in parallel. for whisper or similar tasks, that translates directly into faster processing and lower operational costs, especially when dealing with high-throughput audio processing.
it's a neat trick, but only if you're already running a lot of inference. if you're just running a single test, it probably won't matter. it’s a performance hack that pays off when you’re running heavy workloads.
What To Do
implement speculative decoding in your inference pipeline
Cited By
React
Get the weekly AI digest
The stories that matter, with a builder's perspective. Every Thursday.