Binary and Scalar Embedding Quantization for Significantly Faster & Cheaper Retrieval
What Happened
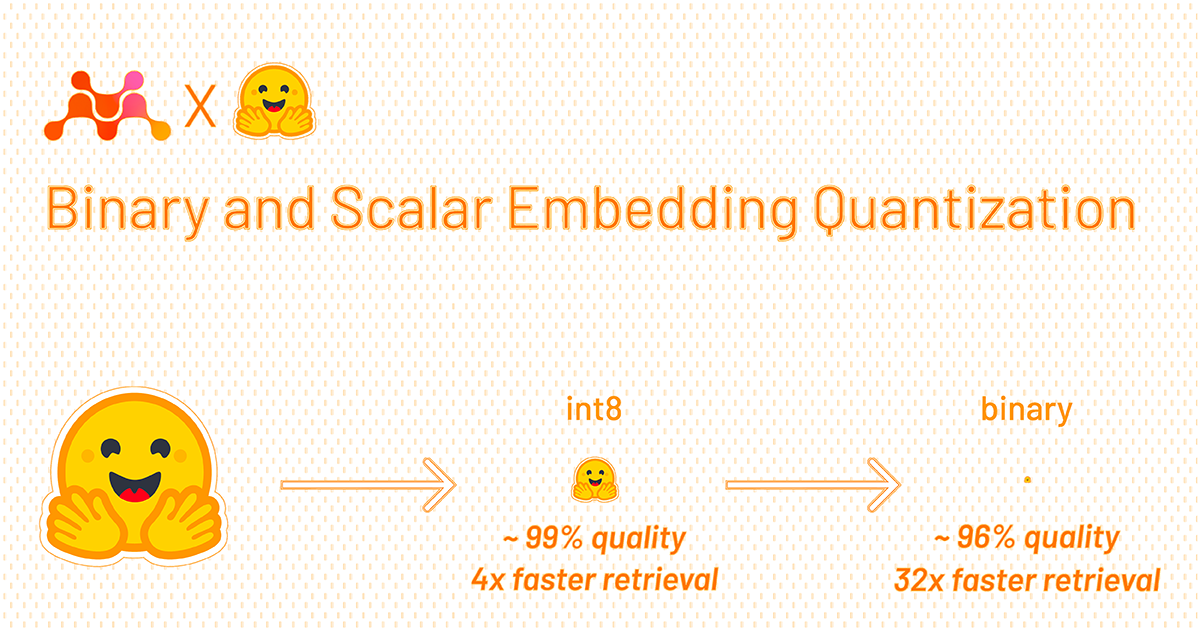
Binary and Scalar Embedding Quantization for Significantly Faster & Cheaper Retrieval
Our Take
this quantization stuff isn't revolutionary; it's just smart optimization. the real payoff comes when you move from 16-bit floats to 8-bit or even binary embeddings. if you're doing high-throughput vector search, saving memory and cutting latency by 30-50% isn't a novelty, it's just good engineering. the cost savings on inference at scale are where the real money is, and these small tweaks, maybe shaving off 4GB of VRAM, add up fast when you're running thousands of queries a minute.
What To Do
implement binary or scalar quantization for all embedding layers in your retrieval system.
Cited By
React
Get the weekly AI digest
The stories that matter, with a builder's perspective. Every Thursday.