Train a Sentence Embedding Model with 1B Training Pairs
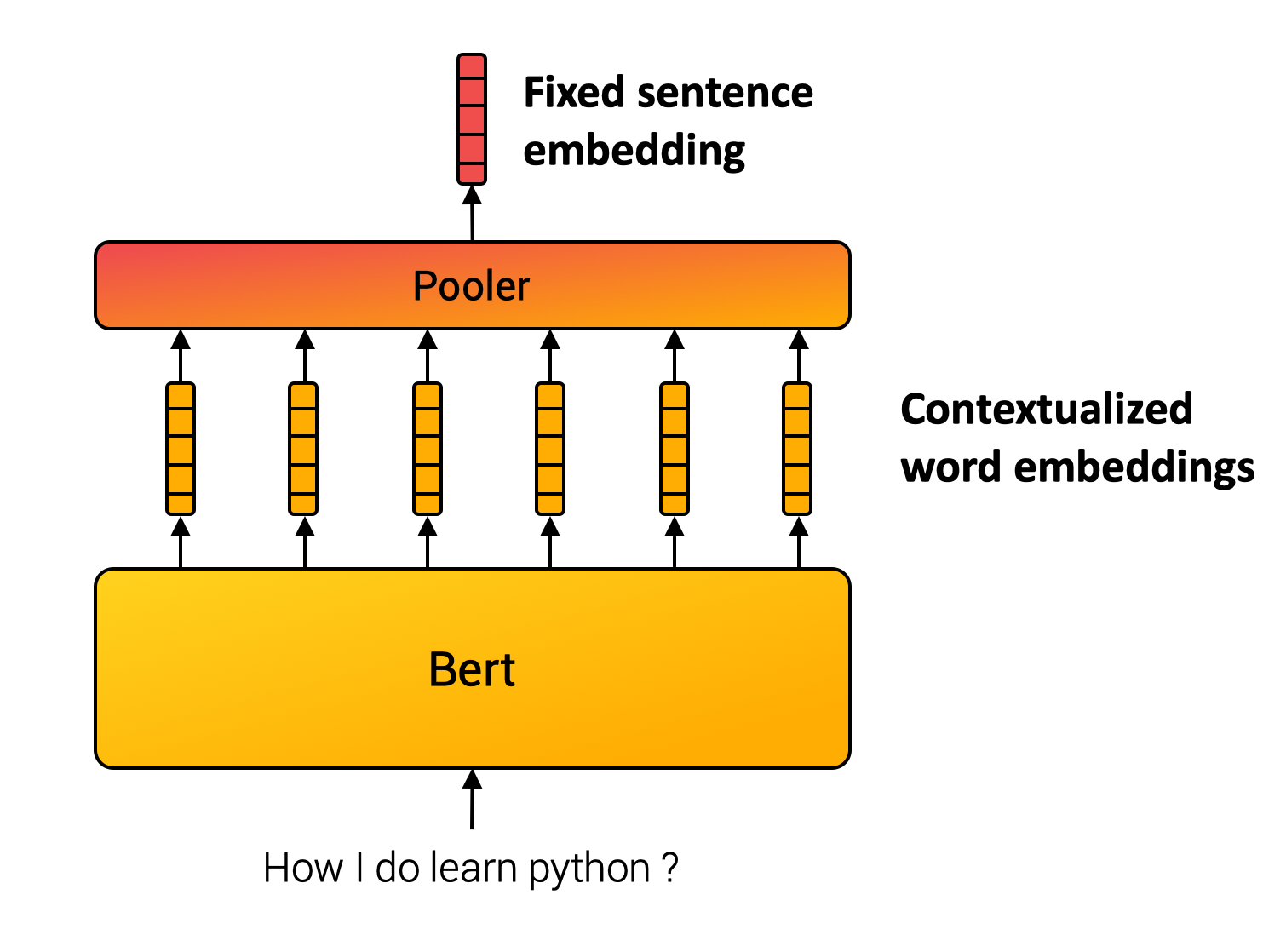
What Happened
Train a Sentence Embedding Model with 1B Training Pairs
Fordel's Take
training a sentence embedding model with 1 billion training pairs? that's just throwing enough data at a model until it stops hallucinating the context. the quality of those 1b pairs is infinitely more important than the sheer quantity. you end up with high-quality, dense representations, but only if the training data covers the actual domain you care about.
we're wasting cycles trying to hit arbitrary dataset sizes. if your 1b pairs aren't relevant, you haven't trained anything meaningful. it's about semantic density, not raw data volume.
look, the next jump isn't about adding more data points; it's about better, more carefully curated context for those points.
What To Do
focus on curating highly specific, domain-relevant training pairs. impact:medium
Cited By
React
Get the weekly AI digest
The stories that matter, with a builder's perspective. Every Thursday.