Retrieval Augmented Generation with Huggingface Transformers and Ray
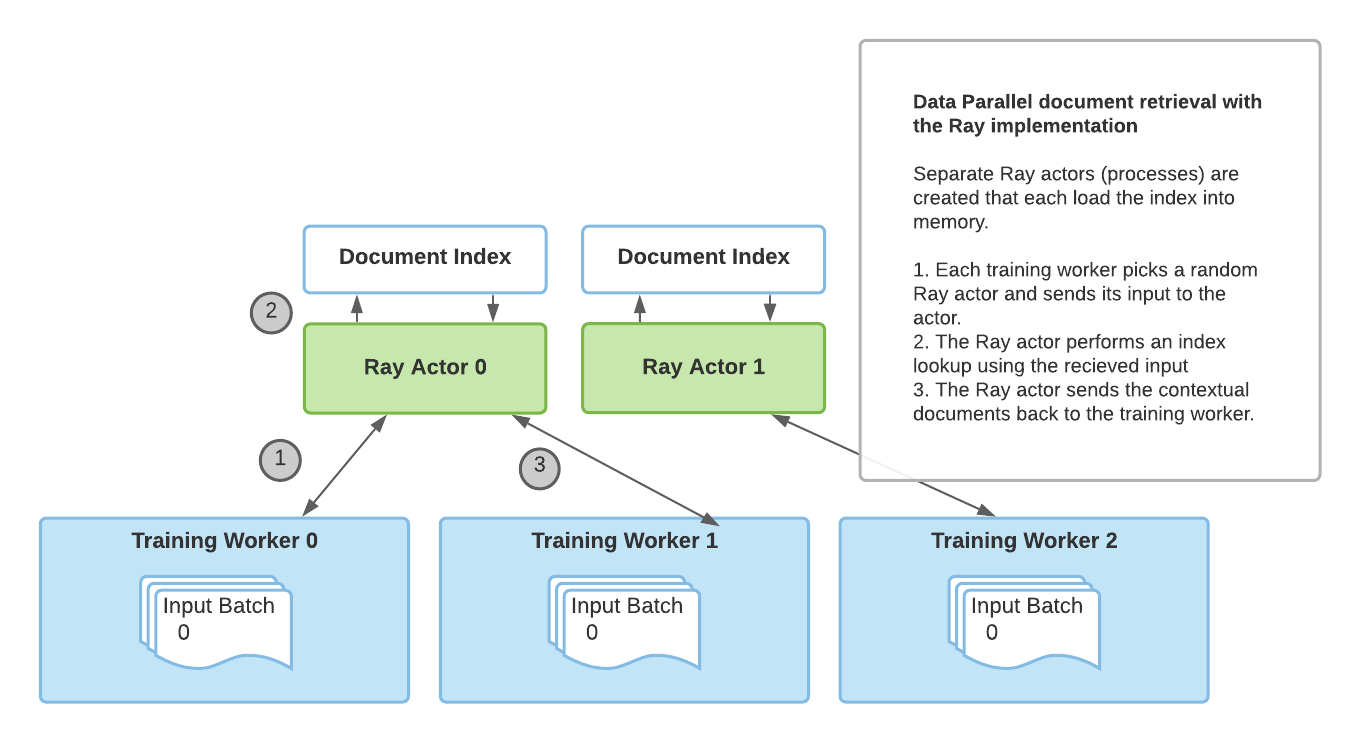
What Happened
Retrieval Augmented Generation with Huggingface Transformers and Ray
Fordel's Take
Ray now supports distributed RAG pipelines using HuggingFace Transformers natively. You can parallelize embedding generation across a GPU cluster using Ray actors without custom orchestration code.
For production RAG, the embedding step — not the LLM call — is the actual throughput bottleneck. Running `sentence-transformers` on a single node while your retrieval corpus scales to millions of chunks is the wrong tradeoff. Most teams optimize the generation end and ignore retrieval infrastructure until latency becomes a crisis.
Teams already hitting embedding throughput limits at scale should adopt this immediately. Single-document hobby RAG projects can ignore it.
What To Do
Use Ray actors to parallelize HuggingFace embedding generation instead of single-node inference because corpus scale will choke retrieval latency long before your LLM becomes the bottleneck.
Cited By
React
Get the weekly AI digest
The stories that matter, with a builder's perspective. Every Thursday.