Large Language Models: A New Moore’s Law?
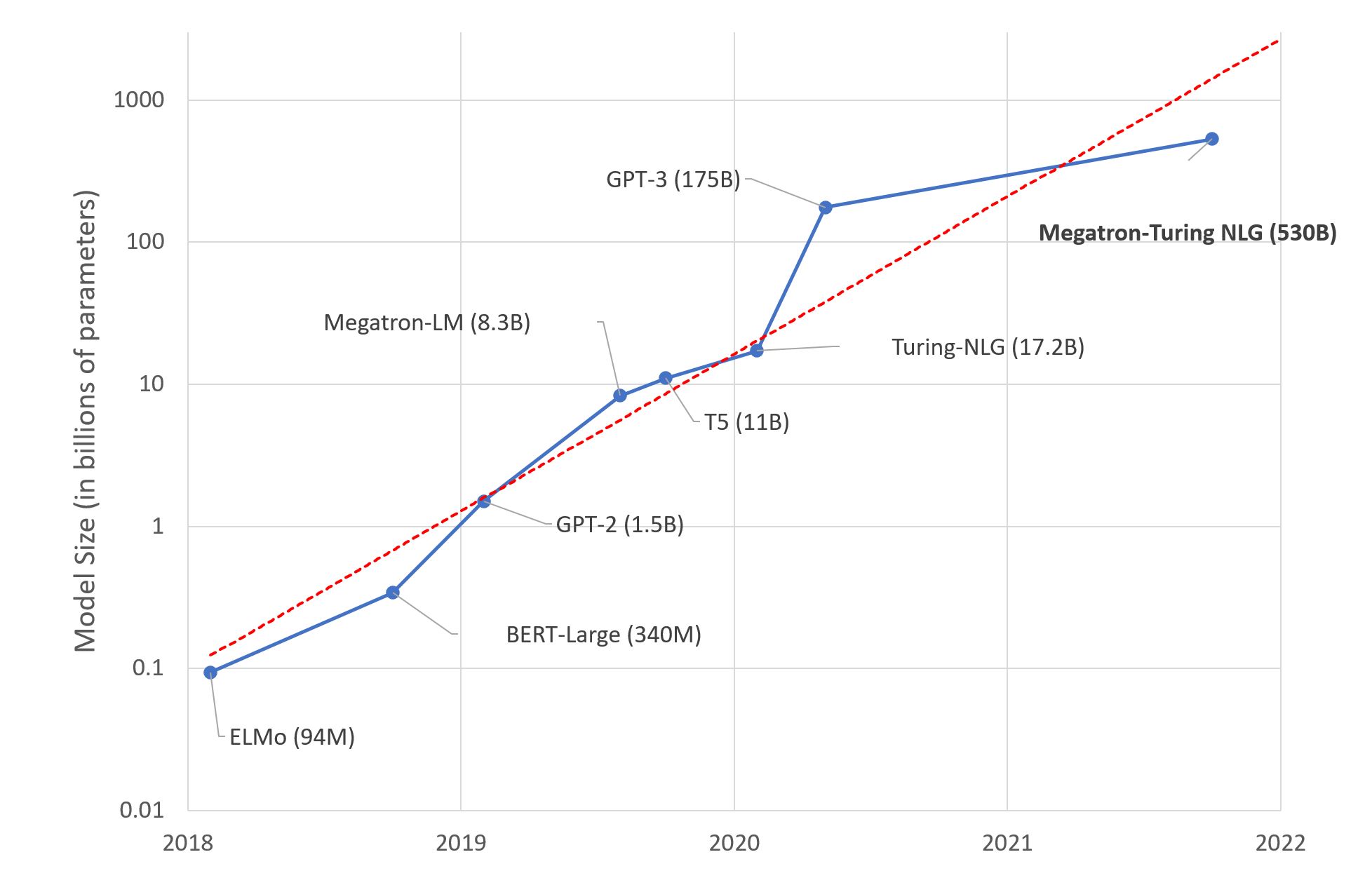
What Happened
Large Language Models: A New Moore’s Law?
Fordel's Take
Since GPT-3, LLM capability-per-dollar has roughly doubled every 8–12 months. GPT-4o now costs 1/20th what GPT-4 cost at launch for equivalent token throughput. No other infrastructure category has deflated this fast.
Teams designing RAG pipelines today are hardcoding cost assumptions that will be wrong within two quarters. Locking every agent call to Claude Opus because it topped your 2024 evals is just burning budget. Claude Haiku or GPT-4o mini handles 80% of classification and extraction tasks at 50x lower cost.
What To Do
Route classification and extraction calls to Claude Haiku instead of Opus because the capability gap is negligible and the cost gap is 50x.
Cited By
React
Get the weekly AI digest
The stories that matter, with a builder's perspective. Every Thursday.