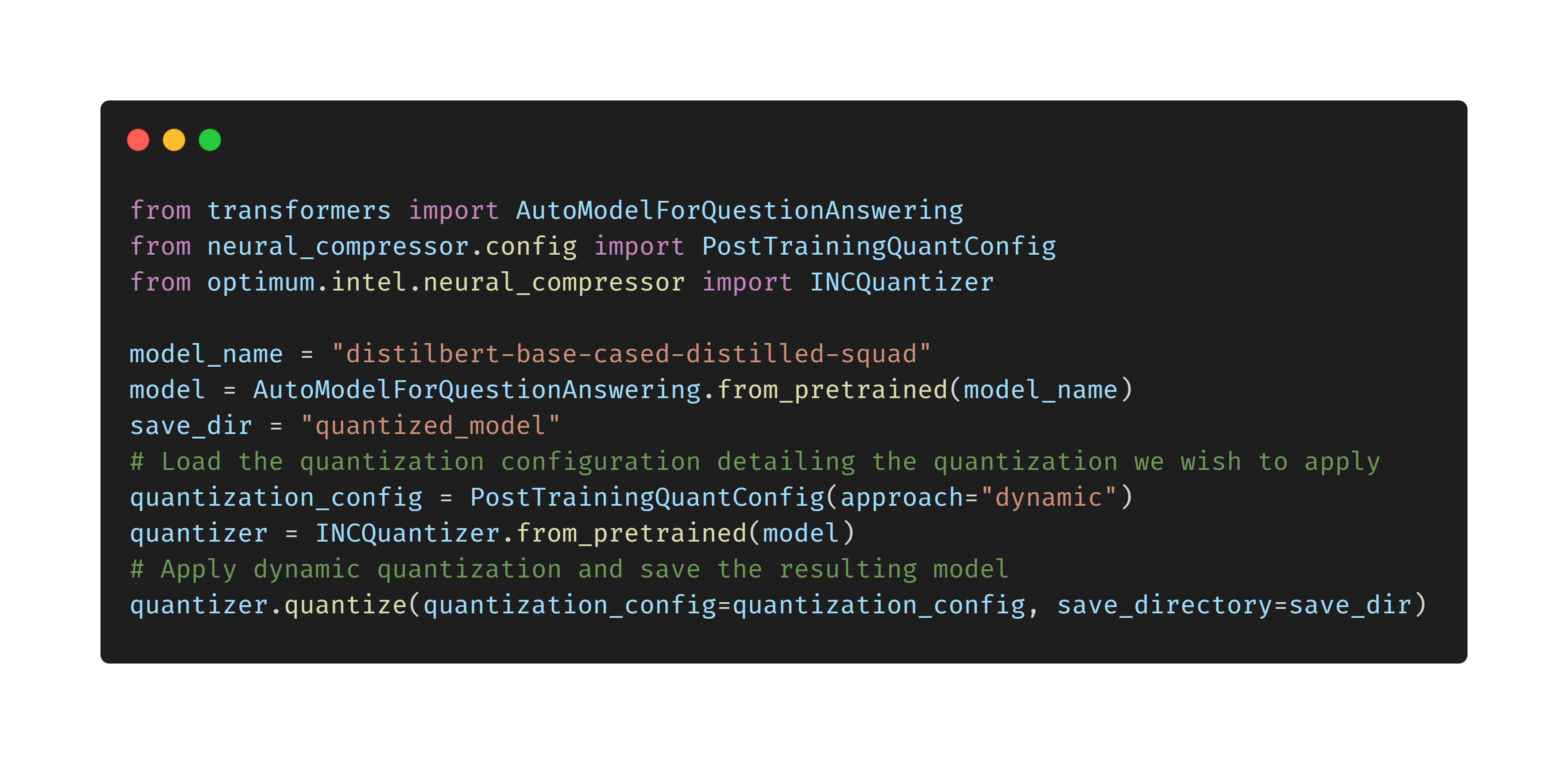
Introducing Optimum: The Optimization Toolkit for Transformers at Scale
What Happened
Introducing Optimum: The Optimization Toolkit for Transformers at Scale
Fordel's Take
honestly? we spend so much time tweaking gradient calculations that we forget the real bottleneck is just running these massive models efficiently. Optimum lets us actually squeeze performance out of the transformers without having to rewrite the core math. it's a necessary abstraction layer, not a magic bullet, but it stops us from wasting compute on stupid memory transfers.
look, when you're pushing models to scale, the latency and memory management is usually where the real money—or time—is lost. this toolkit just handles the heavy lifting of optimization across different hardware setups, which is something we desperately need when deploying 7B parameter models.
it's not a free solution, but it's a way to stop fighting the hardware and start focusing on the actual application logic. we're just building bigger problems with bigger models, and now we at least have a slightly better shovel.
What To Do
Adopt Optimum to reduce infrastructure overhead for large transformer deployments.
Cited By
React
Get the weekly AI digest
The stories that matter, with a builder's perspective. Every Thursday.