Getting Started with Hugging Face Transformers for IPUs with Optimum
What Happened
Getting Started with Hugging Face Transformers for IPUs with Optimum
Fordel's Take
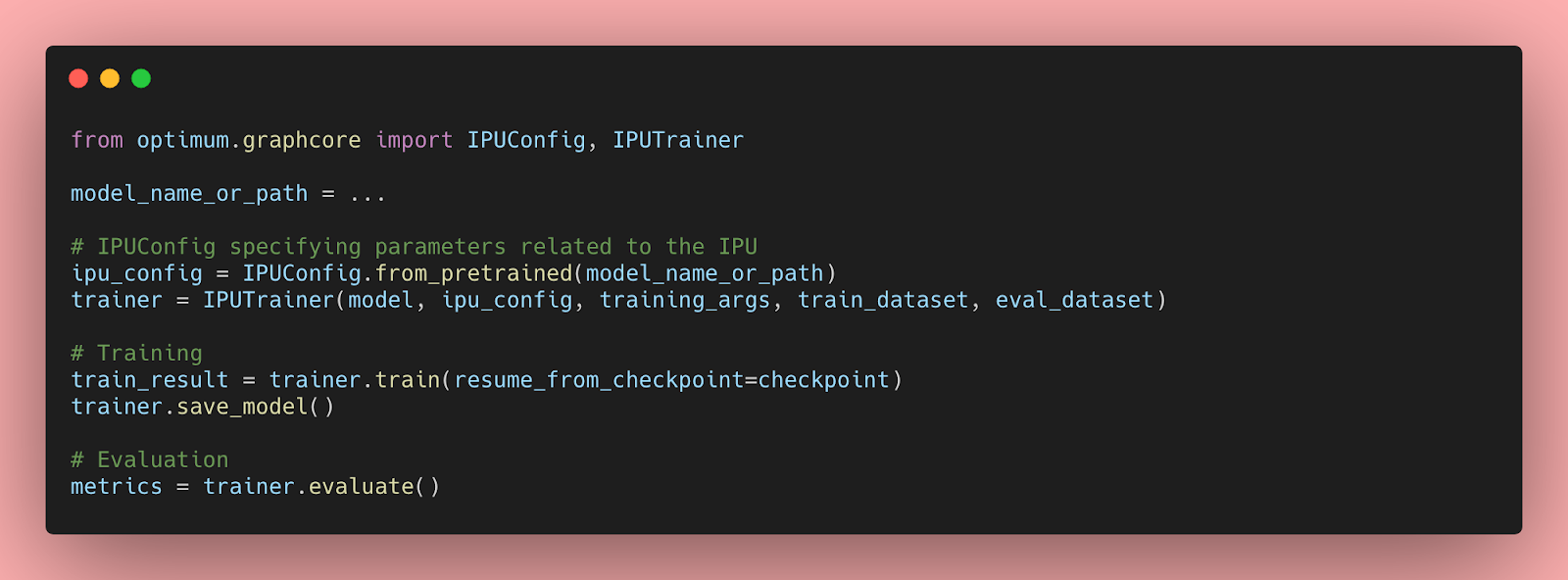
Hugging Face Optimum now supports Graphcore IPUs, letting you run standard Transformer models on IPU hardware with minimal code changes — same pipeline API, different silicon.
For teams running BERT-scale models at inference volume, IPUs offer a different memory architecture that can reduce latency on batch workloads. Most teams never benchmark beyond A100s. Defaulting to GPU without profiling your actual workload is just leaving cost savings on the table.
Teams doing high-throughput text classification or embedding generation should run a cost comparison using Optimum's IPU backend. If your workload fits a single T4 comfortably, skip it entirely.
What To Do
Benchmark Optimum's IPU backend against T4/A10G for BERT-class inference before locking in GPU instance commitments because IPU memory architecture can shift unit economics on batch workloads.
Cited By
React
Get the weekly AI digest
The stories that matter, with a builder's perspective. Every Thursday.