Fine-Tune Wav2Vec2 for English ASR in Hugging Face with 🤗 Transformers
What Happened
Fine-Tune Wav2Vec2 for English ASR in Hugging Face with 🤗 Transformers
Fordel's Take
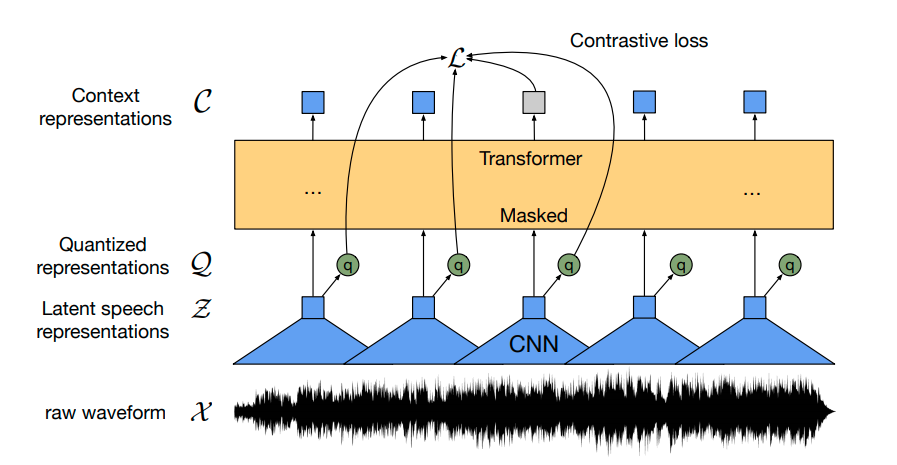
Hugging Face's Transformers library has a documented end-to-end pipeline for fine-tuning Wav2Vec2 on English ASR using CTC loss — covering data collation, WER evaluation, and custom dataset training.
For voice-interface agents in narrow domains — legal, medical, call centers — a fine-tuned Wav2Vec2 can outperform Whisper API at a fraction of inference cost. Most developers default to Whisper without ever benchmarking domain-specific WER, which is just leaving accuracy on the table.
Teams with 10+ hours of labeled domain audio should run this pipeline before locking into a hosted API. Building general English transcription at scale? Whisper large-v3 is still the right call.
What To Do
Fine-tune Wav2Vec2 on your domain audio instead of defaulting to Whisper API because domain-specific WER can drop 15-30% at significantly lower per-hour inference cost.
Cited By
React
Get the weekly AI digest
The stories that matter, with a builder's perspective. Every Thursday.