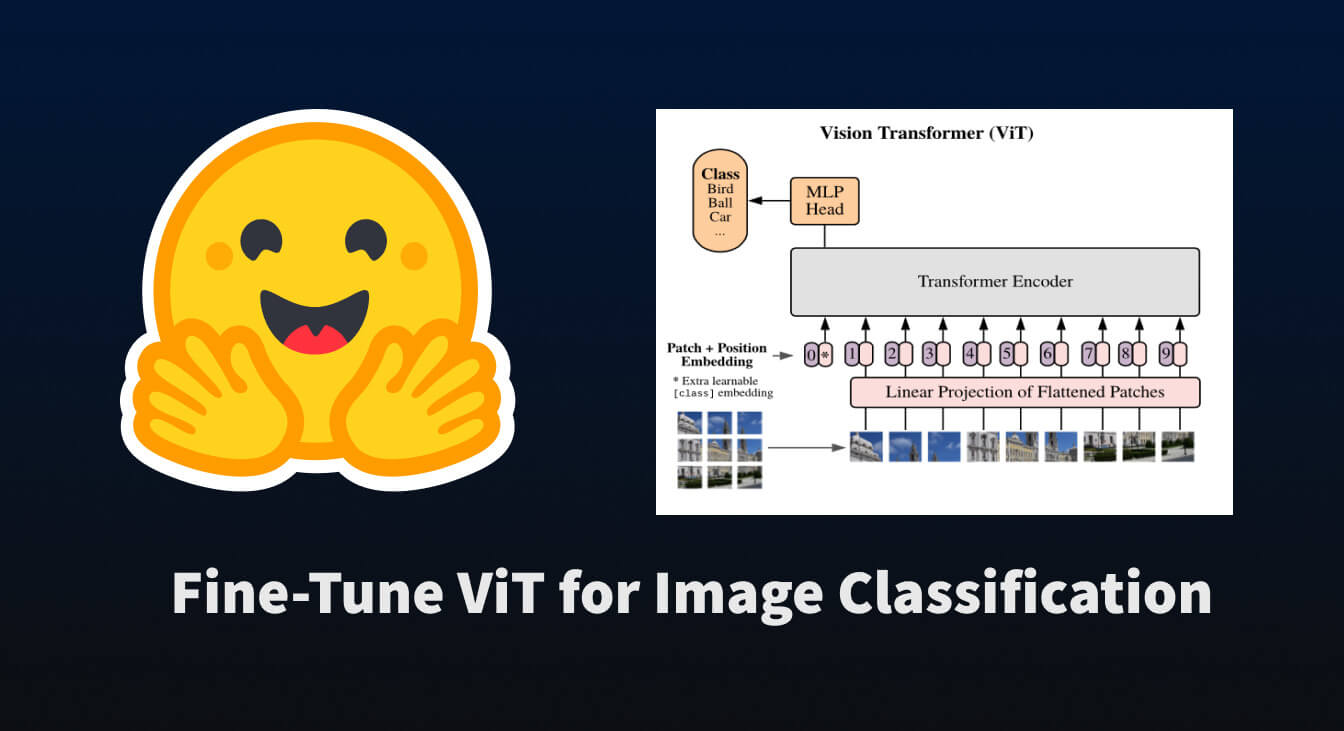
Fine-Tune ViT for Image Classification with 🤗 Transformers
What Happened
Fine-Tune ViT for Image Classification with 🤗 Transformers
Fordel's Take
look, fine-tuning ViT for vision tasks is just the standard pipeline now. it’s not magic; it’s just leveraging massive pre-trained weights. the real cost isn't the fine-tuning itself, it's managing the GPU memory for those large models. if you don't have access to decent VRAM, you're just wasting compute cycles on an expensive setup. it’s mainstream, so don't chase hype, chase deployment efficiency.
we're just applying existing knowledge; stop trying to reinvent the wheel with custom architectures unless you've got a massive dataset to justify the overhead.
What To Do
prioritize deployment infrastructure over bleeding-edge model design
Cited By
React
Get the weekly AI digest
The stories that matter, with a builder's perspective. Every Thursday.