Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel
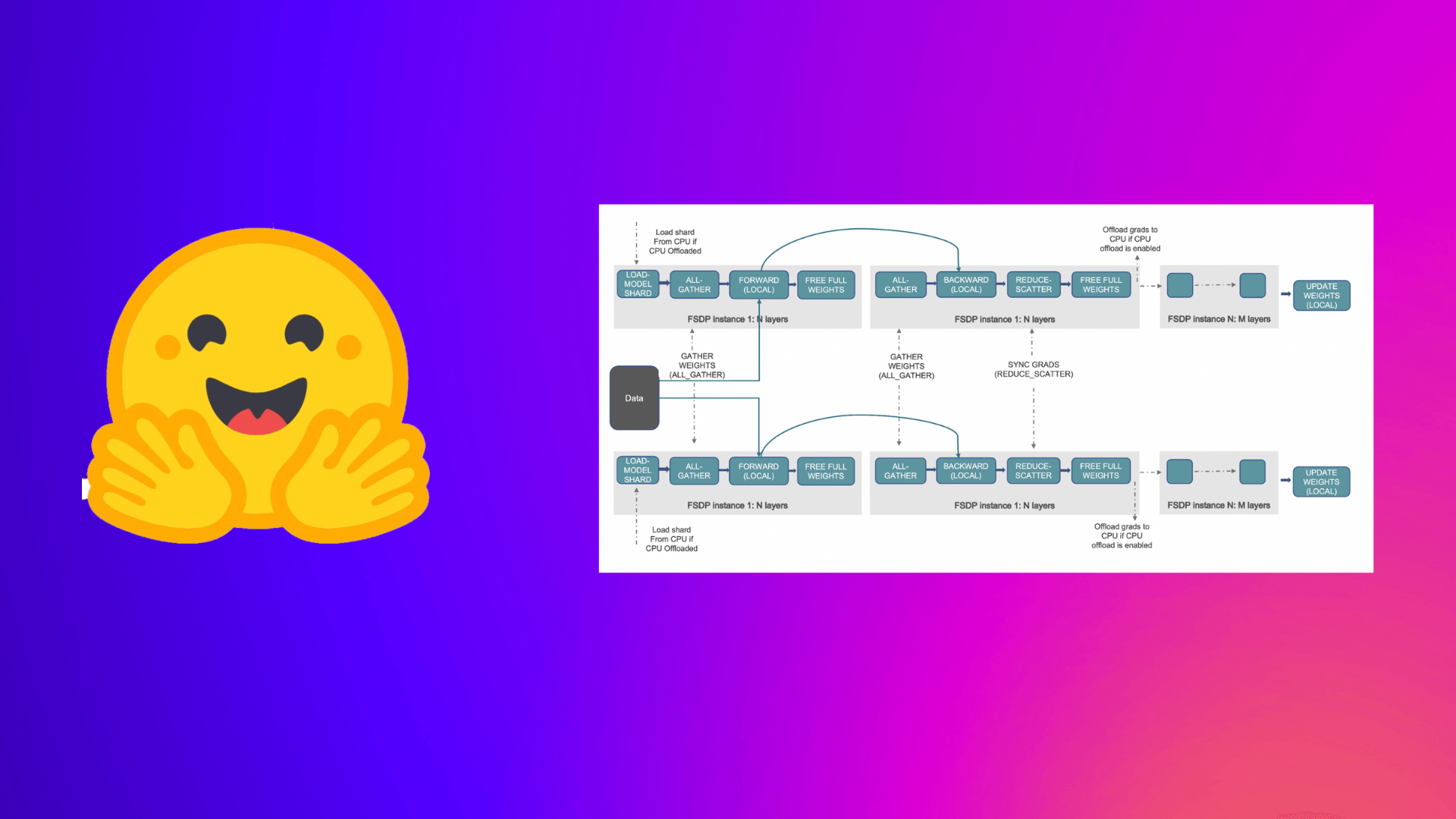
What Happened
Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel
Fordel's Take
honestly? we're still fiddling with sharding techniques just to squeeze training time out of these massive models. using PyTorch FSDP is technically the right move, it just forces you to understand distributed memory management better than you actually need to. it's a necessary headache for big clusters, but it ain't magic.
look, the real cost isn't the code; it's the infrastructure setup. getting FSDP running smoothly on multi-node systems still involves debugging networking and memory allocation, which eats up development time we don't have.
we can't just throw more GPUs at it and expect faster results. it's about efficient utilization, not just raw compute power. if you aren't sharding correctly, you're just wasting cycles, period.
What To Do
benchmark FSDP performance on your specific cluster setup to ensure you're actually seeing gains. impact:high
Cited By
React
Get the weekly AI digest
The stories that matter, with a builder's perspective. Every Thursday.